AI Agent Platform
View details

LLM Caching for Faster Agent Workflows
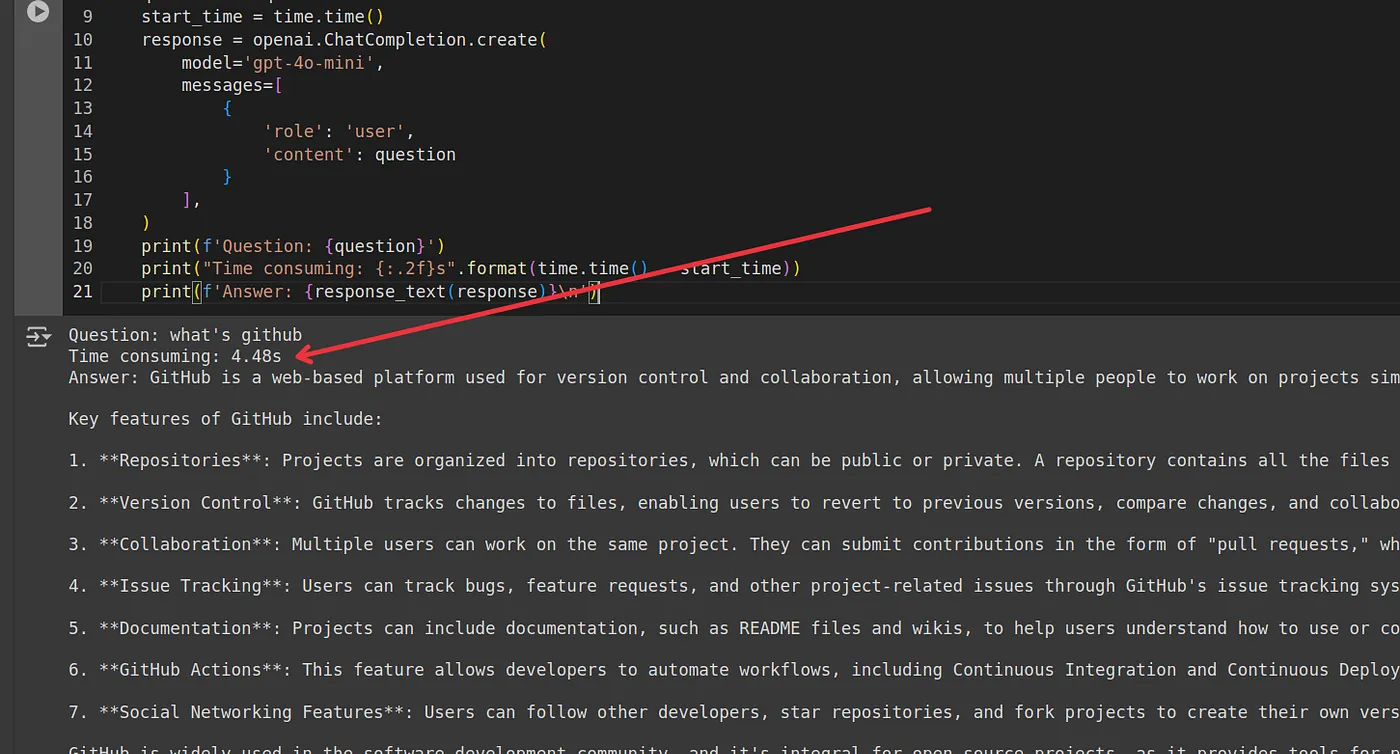
Enterprise agent workflows often repeat the same retrieval, classification, summarization, and planning steps. Without caching, teams pay extra model cost and wait through avoidable latency every time an agent run starts.
LLM caching stores safe, reusable outputs for deterministic or near-deterministic steps. In a B2B SaaS environment, that can include policy summaries, normalized product knowledge, account brief sections, routing decisions, and evaluation rubrics.
Not every agent response should be cached. Linkinfra AI focuses caching on stable workflow components with clear inputs, versioned context, and traceable ownership. This keeps speed improvements from weakening correctness or governance.
Teams can set cache rules by workspace, workflow, model, tool, or data source. When source knowledge changes, the platform can expire affected results and force fresh reasoning.
Well-designed caching cuts repeated token spend, improves response time, and makes common workflow outputs more consistent. It also gives operators a cleaner baseline when evaluating agent changes.
Linkinfra AI surfaces cache hit rates, model cost, latency, and quality signals so teams can decide where caching improves the workflow and where fresh model calls are still required.
The goal is simple: faster agents without turning enterprise automation into an opaque shortcut.
